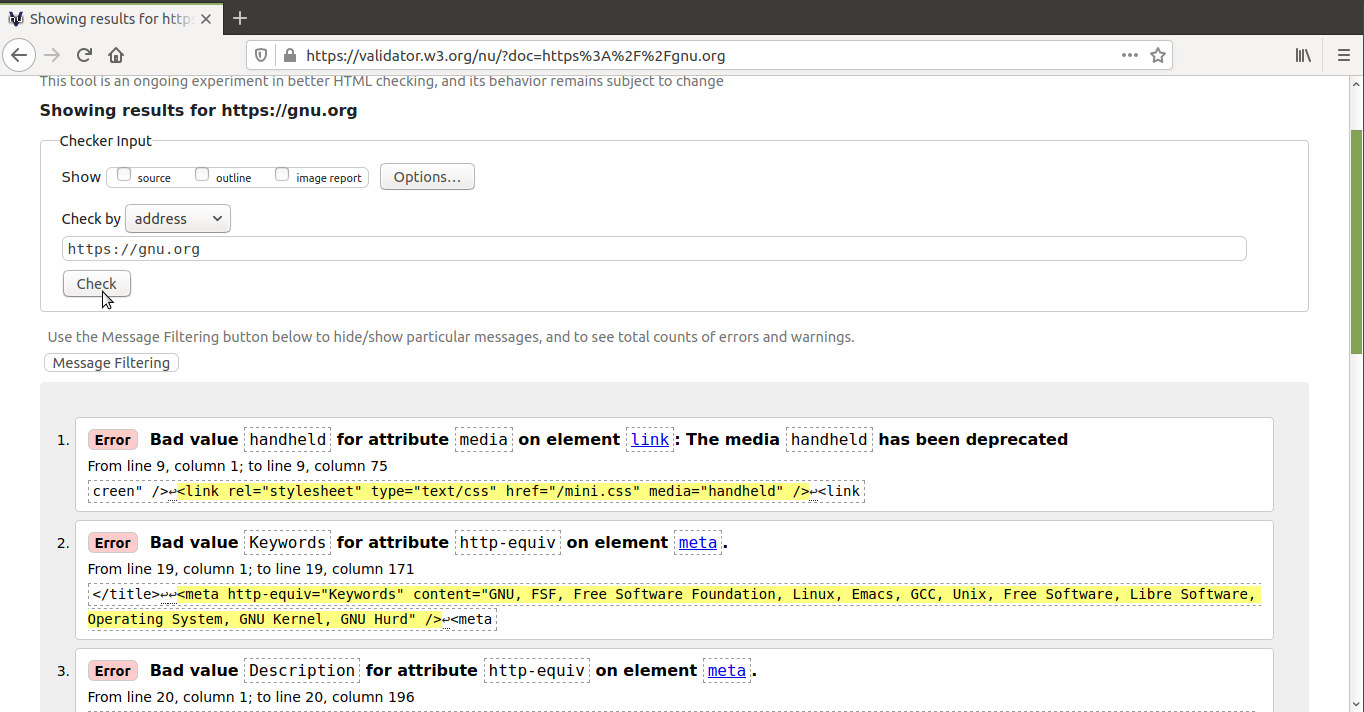
Kelkfoje utilas prezenti datumojn per arba strukturo kiel tiu, kiun
kreas la tree-programo. La tree-programo kreas eligon de arbo de
dosierujoj kiel tiu ĉi:
✔ /var/www/html/Repos/Freak-Spot/freak-theme [master|✔] $ tree
.
├── static
│ ├── css
│ │ └── style.css
│ ├── genericons
│ │ ├── COPYING.txt
│ │ ├── genericons.css
│ │ ├── Genericons.eot
│ │ ├── Genericons.svg
│ │ ├── Genericons.ttf
│ │ ├── Genericons.woff
│ │ ├── LICENSE.txt
│ │ └── README.md
│ ├── images
│ │ ├── creativecommons_public-domain_80x15.png
│ │ ├── gnu-head-mini.png
│ │ └── questioncopyright-favicon.png
│ └── js
│ ├── functions.js
│ └── jquery-3.1.1.js
└── templates
├── archives.html
├── article.html
├── article_info.html
├── author.html
├── authors.html
├── base.html
├── category.html
├── index.html
├── page.html
├── pagination.html
├── period_archives.html
├── tag.html
├── taglist.html
└── tags.html
6 directories, 28 files
Por prezenti la komandon tiel, kiel ĝi aperas en terminalo, mi uzis la
HTML-etikedojn <samp> kaj <pre> (<pre><samp>eliro de
tree</samp></pre>). Sed kio okazas, se mi volas inkludi ligilon aŭ uzi
aliajn HTML-elementojn, aŭ CSS? Tiuokaze ni devas uzi CSS por montri la
branĉan aspekton.