

Viele Menschen denken, dass Kryptowährungen anonym sind, aber das ist nicht der Fall. Die meisten von ihnen sind pseudoanonym, da Transaktionen nachverfolgt werden können und somit offenbaren, wem Weiter lesen Kryptowährungen, Anonymität, dezentrale Wirtschaft

Warum kann man mit Telegram nicht anonym chatten
Telegram wurde 2013 ins Leben gerufen und hat sich seitdem zu einer der am meisten genutzten Messaging-Apps entwickelt. Einige Leute nutzen Telegram, um mit Familie und Freunden zu kommunizieren, während andere es nutzen, um in Gruppenchats oder Kanälen, wo eine oder wenige Personen Inhalte an Millionen von Abonnenten senden können, informiert zu bleiben.
Mit Telegram kann man selbstzerstörende Nachrichten und große Dateien senden, Bots erstellen und nutzen, verschlüsselte Sprachanrufe und Videoanrufe starten, und die meisten Dinge tun, die man von einer Messaging-App erwarten kann, wie zum Beispiel Audionachrichten, Sticker und Emojis schicken.
Was ist also das Problem mit diesem Programm? Telegram vermittelt manchen Menschen ein falsches Gefühl von Privatsphäre, das überhaupt nicht gerechtfertigt ist. Das liegt vor allem an der irreführenden Werbung: Telegram behauptet, quelloffen und Ende-zu-Ende-verschlüsselt zu sein. Selbst wenn diese täuschenden Behauptungen vollständig wahr wären, hat die beliebte Messaging-App noch andere ernsthafte Probleme, die deine Privatsphäre gefährden.
Unverschlüsselt, proprietär, zentralisiert: ein Alptraum für die Privatsphäre
Nur der Client-Code von Telegram ist frei, aber dieser Code ist ohne die Backend-Software und die proprietäre Infrastruktur nutzlos. Diese Kernkomponenten werden von einem einzigen Unternehmen kontrolliert, das leicht gezwungen werden kann, die Anforderungen der Behörden zu erfüllen. Im August 2024 wurde der Telegram-Chef von französischen Behörden verhaftet, die Informationen über die Nutzer der App verlangten. Er gab nach und zeigte der Welt, dass diene privaten Gespräche, Telefonnummern, IP-Adressen, Fotos usw. nicht sicher sind.
Die Finanzierung von Telegram hängt von bezahlten Abonnements und Anzeigen ab. Wer kann dir versichern, dass sie in Zukunft ihre Einnahmequellen nicht erweitern werden, indem sie dir Anzeigen anbieten, die auf den von dir gesendeten und empfangenen Inhalten basieren, oder eine KI trainieren.
Was hält Telegram-Mitarbeiter, Hacker oder Regierungsspione davon ab, diene Nachrichten zu lesen? Nichts. Nachrichten auf Telegram sind standardmäßig nicht verschlüsselt, sodass die Nutzer ungeschützt sind. Sicher, sie könnten einen „geheimen Chat“ initiieren, was ziemlich unpraktisch ist, denn man muss auf verschiedene Knöpfe tippen, um auf diese Option zuzugreifen, und warten, bis der andere Benutzer eine Verbindung hergestellt hat, bevor man Nachrichten senden kann. Um die Sache noch schlimmer zu machen, ist diese Funktion weder in der Web- noch in der Desktop-Version verfügbar und würde wahrscheinlich Verdacht erregen. Optionale Privatsphäre macht die Nutzer, die sich dafür entscheiden, aus der Masse herausstechen.
Du wirst verfolgt
Vergiss es, bei Telegram anonym zu bleiben. Bevor du überhaupt chatten kannst, musst du eine Telefonnummer angeben, die leicht mit deiner echten Identität verknüpft werden kann. Als Lösung kannst du ein Wegwerf-Handy verwenden und Telegram auf deinem Computer nutzen. Doch was, wenn du es auf einem Handy nutzen möchtest? Du müsstest technisch versiert genug sein, um ein datenschutzfreundliches Handy-Betriebssystem zu installieren, und verhindern, vom Mobilfunknetz verfolgt zu werden.
Eine Möglichkeit, deine Identität zu schützen, besteht darin, für eine Remote-SMS-Verifizierung mit Monero zu bezahlen (SMSpool bietet diesen Dienst an) und Telegram auf einem freien Betriebssystem zu verwenden. Wenn du Angst hast, dass Telegram dich wieder nach einer Verifizierung fragt und du das gleiche Konto weiter benutzen willst, kannst du eine Handynummer (die nichts mit deiner Identität zu tun hat) kaufen oder sie für einen längeren Zeitraum mieten.
Kurz gesagt, die Verwendung von Telegram mit Privatsphäre oder Anonymität ist übermäßig kompliziert, daher ist es kein empfehlenswertes Programm für diese Zwecke. Wenn dich jemand einlädt, Telegram zu benutzen, um über sensible Themen zu sprechen, vermeide es, dich in die Höhle des Löwen zu wagen. Schlage vor, das persönlich zu tun oder verwende eine freie, dezentralisierte und anonyme Alternative (wie SimpleX, Delta Chat oder Briar).

Warum Kryptowährungen einen Wert haben
Für viele Menschen ist es schwer zu verstehen, warum Kryptowährungen wertvoll sind. Sie denken, dass sie keinen Wert haben können, wenn sie nicht von einer Regierung oder etwas Greifbarem gestützt werden.
Kryptowährungen haben einen Wert, weil die Nutzer Vertrauen in sie haben. Das ist ähnlich wie bei Fiatgeld und Gold. Wenn niemand daran glauben würde, dass sie einen Wert haben, wären sie wertlos. Aber warum haben die Menschen Vertrauen in Bitcoin und andere Kryptowährungen? Abgesehen von einem Netzwerk, das seit 2009 reibungslos funktioniert, hat Bitcoin etwas, das ihn von Fiatgeld unterscheidet: Er ist knapp. Es wird nie mehr als 21 Millionen Bitcoins geben.
Die Zentralbanken drucken im Gegenteil so viel Geld wie sie wollen, um die Wirtschaft von oben zu steuern. Da es immer mehr Geld gibt, ist es immer weniger wert.
Deshalb wird Bitcoin, gemessen in Euro oder Dollar, immer wertvoller. Diese digitale Knappheit wurde im Bitcoin-Protokoll geschaffen, um den Wert der Währung zu erhalten. Es ist zwar möglich, eine weitere Blockchain ähnlich wie Bitcoin zu erstellen (da Bitcoin ein freies Programm ist) und so mehr Münzen zu erzeugen, aber nicht jeder würde die Klonwährung annehmen, da der Wert hauptsächlich in der Gemeinschaft der Nutzer und dem über die Jahre erworbenen Vertrauen liegt. Es gibt viele verschiedene Währungen, die versuchen, mit Bitcoin zu konkurrieren, aber sie haben nur einen Wert, weil sie eine andere Funktionalität bieten und eine Gemeinschaft hinter sich haben.
Wie kann etwas Digitales knapp sein?
Im Gegensatz zu anderen digitalen Vermögenswerten, die unbegrenzt kopiert und eingefügt werden können, arbeiten Kryptowährungen dezentral mit einem Konsensmechanismus, der ihre Sicherheit und Knappheit gewährleistet. Dieser Konsensmechanismus variiert von Kryptowährung zu Kryptowährung. Der erste verwendete Konsensmechanismus basiert auf einem Prozess, der als Proof of Work bekannt ist und bei dem Computer, so genannte Schürfer, miteinander konkurrieren, um mathematische Probleme zu lösen und Transaktionen zu validieren.
Da die Schürfer für das Schürfen eine finanzielle Belohnung erhalten, gibt es ein großes Netzwerk von Computern, die das Netzwerk dezentralisiert und rund um die Uhr am Laufen halten. Der Proof of Work macht es fast unmöglich, eine Transaktion rückgängig zu machen oder zu ändern, sobald sie Teil der Blockchain ist. Da das Netzwerk von einer großen Zahl von Akteuren validiert wird, die für ihren Beitrag eine Belohnung erhalten und daher ein Interesse am ordnungsgemäßen Funktionieren des Netzwerks haben, ist es wirtschaftlich nicht rentabel, mehr als 50 % des Netzwerks anzuhäufen, um die Blockchain böswillig zu verändern.
Es wird immer weniger Geld in Umlauf gebracht
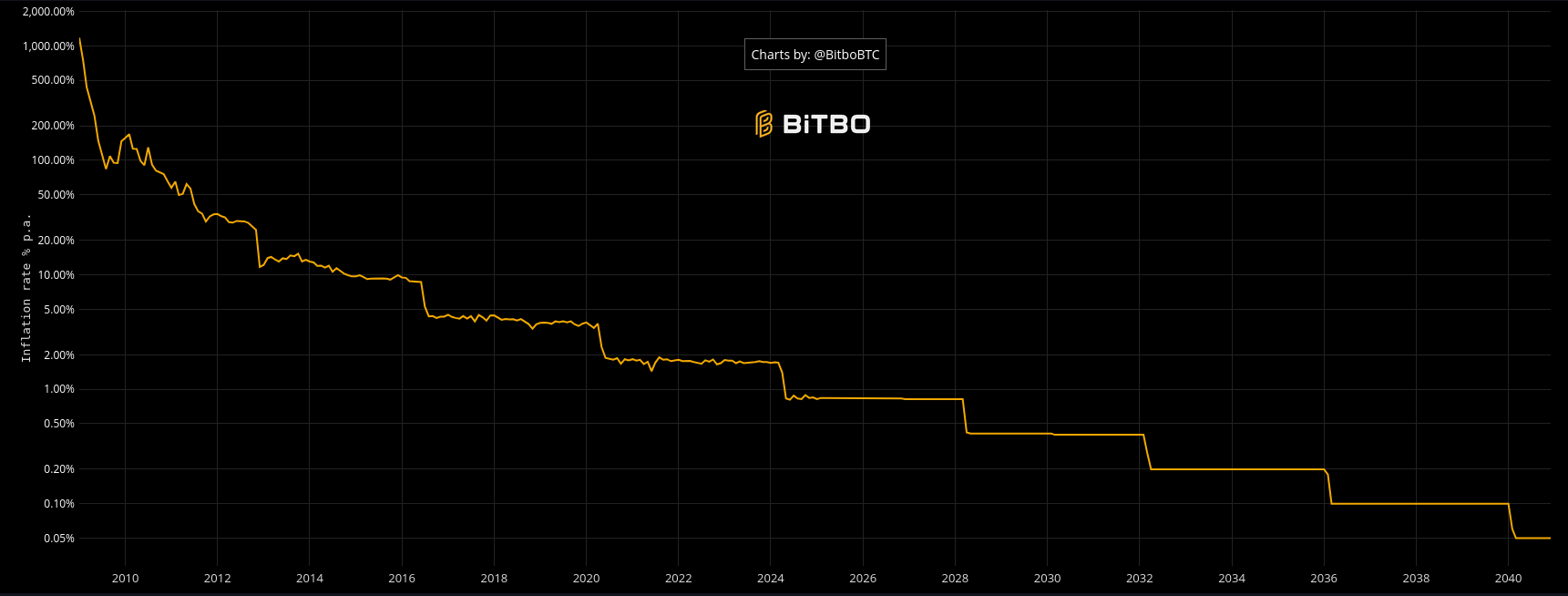
Alle vier Jahre reduziert Bitcoin die Belohnungen für die Schürfer um die Hälfte, so dass immer weniger Münzen im Umlauf gebracht werden. Im Jahr 2140 wird die Bitcoin-Inflation 0 % betragen, das heißt, es werden keine neuen Münzen im Umlauf gebracht. Die Schürfer werden dann weiterhin Belohnungen erhalten, da sie für die Validierung von Transaktionen Gebühren erhalten. Die Bitcoin-Inflation ist derzeit niedriger als die von Gold, was den Bitcoin zu einem der begehrtesten und am schnellsten im Wert wachsenden Vermögenswerte macht.
Keine zentrale Instanz kann deine Bitcoins kontrollieren oder konfiszieren
Ein weiterer Anreiz, der Bitcoin wertvoll macht, ist, dass er weder von Banken noch von anderen Personen konfisziert werden kann. Auch können Zahlungen nicht rückgängig gemacht werden, wie im traditionellen Bankensystem. Wenn du deinen privaten Schlüssel sicher aufbewahrst, kann dir niemand dein Vermögen wegnehmen.
Man kann mit Bitcoin international handeln
Dank der Blockchain-Technologie ist es möglich, mit jedem auf der Welt zu handeln, der Zugang zum Internet hat. Kryptowährungen haben Anerkennung und Nutzer auf der ganzen Welt gewonnen, wodurch ihr Wert gestiegen ist.
Fazit
Solange es das Internet und Menschen gibt, die diese Technologie schätzen und an sie glauben, werden Bitcoin und ähnliche Kryptowährungen langfristig weiter an Wert steigen, da sie deflationär sind. Menschen, die Fiatgeld horten, werden hingegen mit der Zeit an Kaufkraft verlieren, wenn die Zentralbanken weiterhin mehr Geld ausgeben.
Die Umweltauswirkungen von Fiatgeld
Ignoranten sprechen über die Umweltauswirkungen von Kryptowährungen. Sie haben keine Ahnung. Wie viele Kriege haben Fiat-Währungen und die Machtspiele von Politikern und Zentralbankern verursacht?
Fiat-Währungen sind inflationär und fördern so das Wirtschaftswachstum (auf wessen Kosten und zu wessen Lasten?). Diese Inflation mildert auch die die Verschuldung der Staaten, sie ist wie eine unsichtbare Steuer für die Armen und finanziell ungebildeten Menschen.
Dumme Journalisten, Zentralbanker und Politiker versuchen die finanzielle Unabhängigkeit und Privatsphäre mit Verboten und einseitigen Nachrichten einzuschränken. Sie haben keinen Erfolg und werden ihn auch nicht haben. Das wäre so, als würde man versuchen, Edelmetalle zu verbieten.
Es gibt Kryptowährungen, die Scheiße sind, die keine Privatsphäre bieten usw., aber man kann sie nicht alle in einen Topf werfen. Außerdem sind Auswirkungen auf die Umwelt im Vergleich zu Fiat-Währungen minimal. Es gibt Kryptowährungen, die die Umwelt mehr belasten als andere, natürlich. Für diejenigen, die mehr umweltbewusst sind, gibt es Kryptowährungen, die keine Proof-of-Work-Algorithmen verwenden.
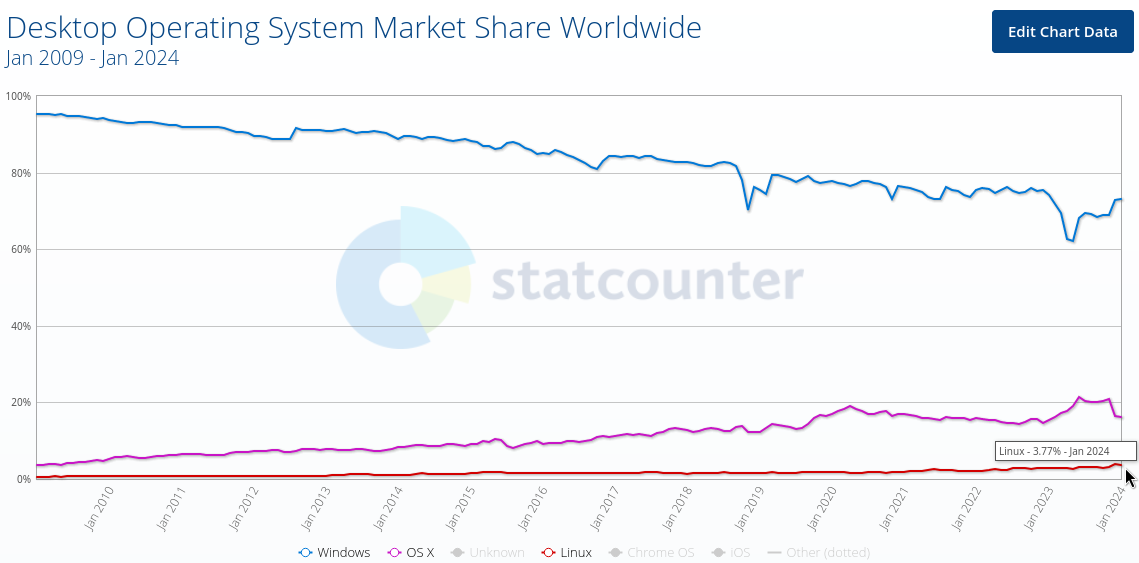
Fast 4 % der PCs verwenden GNU/Linux
Nach Daten von Statcounter wird GNU/Linux auf 3,77 % der PCs (Laptops und Desktops) verwendet Weiter lesen Fast 4 % der PCs verwenden GNU/Linux