Ein CAPTCHA ist ein Test, der ermöglicht die Unterscheidung zwischen Menschen und Computern. Er wird hauptsächlich verwendet, um Spam zu vermeiden.
Ein Programm, das diesen Test durchführt, ist reCAPTCHA, das am 27. Mai 2007 veröffentlicht und im September 2009 von Google übernommen wurde1. Dieses Programm wird auf Websites in der ganzen Welt verwendet.
reCAPTCHA wurde dank der unentgeltlichen Arbeit von Millionen von Nutzern, die in der Lage sind, für Computer unverständliche Wörter zu erkennen, häufig zur Digitalisierung von Texten eingesetzt. Die große Mehrheit der Menschen weiß nicht dass Google sich ihre Arbeit zunutze macht; anderen ist es egal.
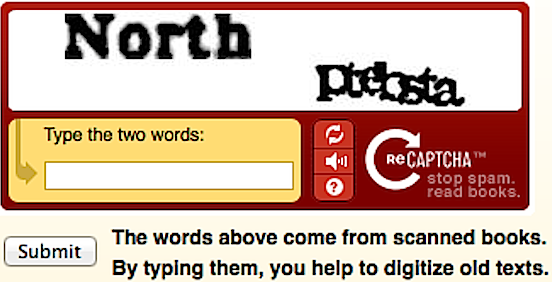
In dem Artikel „Deciphering Old Texts, One Woozy, Curvy Word at a Time“, der in der Zeitung The New York Times veröffentlicht wurde, wurde berichtet, dass Internetnutzer die Digitalisierung der Archive dieser Zeitung (die seit 1851 erscheint) mit Hilfe von reCAPTCHA abgeschlossen haben. Wie der Schöpfer von reCAPTCHA damals sagte, entschlüsselten die Nutzer, oder besser gesagt „die gebrauchten Menschen“, etwa 200 Millionen CAPTCHAs pro Tag, wobei sie etwa 10 Sekunden für die Lösung jedes einzelnen benötigten. Dies entspricht 500.000 Stunden Arbeit pro Tag2.
Ein CAPTCHA kann nicht nur bei schwer verständlichem Text, sondern auch bei Bildern verwendet werden. Google verwendet reCAPTCHA zum Beispiel auch, um Bilder von Geschäften, Verkehrsschildern usw. zu identifizieren, die für Google Maps erstellt wurden. Darüber hinaus werden die reCAPTCHAs von Google für andere, den Nutzern unbekannte Zwecke verwendet.

Nur Google kennt den wirtschaftlichen Nutzen, den dieses System der Ausbeutung bietet. Es ist unmöglich, reCAPTCHA zu überprüfen, da es sich um proprietäre Software handelt und die „Genutzte“ keine Macht haben. Das einzige, was sie tun können, ist, Lösungen von CAPTCHAs wie die von Google abzulehnen, damit sie nicht mehr verwendet werden.
Jetzt verwendet Google eine Identifizierungsmethode, die seinen „Genutzte“ Zeit spart und sie von der Entschlüsselung von Texten und Bildern entbindet. Die Nutzer müssen nur noch einen Knopf drücken. Dieser Mechanismus erzwingt die Ausführung von JavaScript-Code, der den Nutzern unbekannt ist, was ein großes Risiko für die Privatsphäre darstellen kann. Google kann von den Nutzern, die diesen Mechanismus verwenden, viele Informationen erhalten, die wahrscheinlich für eine beträchtliche Summe verkauft werden.
Außerdem diskriminiert reCAPTCHA behinderte Nutzer und Tor-Nutzer: Einerseits sind die Aufgaben für behinderte Menschen länger und schwieriger zu lösen; andererseits müssen diejenigen, die privat im Internet surfen, eine schwierigere Aufgabe lösen, die mehr Zeit erfordert.
Der Artikel, von dem Ersteller von reCAPTCHA geschrieben3, als es von Google übernommen wurde, sagte:
Die Verbesserung der Verfügbarkeit und Zugänglichkeit aller Informationen im Internet ist uns sehr wichtig, daher freuen wir uns darauf, diese Technologie zusammen mit dem reCAPTCHA-Team weiterzuentwickeln.
Dennoch ist die mit reCAPTCHA durchgeführte Arbeit in den meisten Fällen nicht verfügbar oder zugänglich. Die Daten werden auf eine Weise präsentiert, die Google und anderen Unternehmen wirtschaftlich zugute kommt. Die Nutzer, die an der Digitalisierung des Archivs der New York Times mitgewirkt haben, müssen dafür bezahlen, dass sie sich Anzeigen ansehen, wenn sie das Archiv konsultieren, an dessen Digitalisierung sie selbst mitgewirkt haben, ohne dafür eine Gegenleistung zu erhalten.
-
Deciphering Old Texts, One Woozy, Curvy Word at a Time (2011-3-28). The New York Times. Abgerufen 2017-5-5. ↩
-
Teaching computers to read: Google acquires reCAPTCHA (2009-9-16). Official Google Blog. Abgerufen 2017-5-5. ↩