
Um CAPTCHA é uma prova que se realiza para diferenciar computadores de humanos. Usa-se principalmente para evitar mensagens lixo (em inglês chamados de spam).
Um programa que realiza este teste é o reCAPTCHA, que foi lançado a 27 de maio de 2007 e adquirido pelo Google em setembro de 20091. É utilizado em sítios eletrónicos de todo o mundo.
O reCAPTCHA tem sido amplamente utilizado para digitalizar textos graças ao trabalho gratuito de milhões de utilizadores, que são capazes de identificar palavras incompreensíveis para os computadores. A grande maioria desconhece que o Google está se aproveitando seu trabalho; outros não se importam.
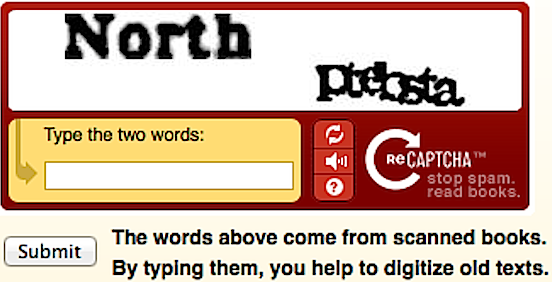
O artigo «Deciphering Old Texts, One Woozy, Curvy Word at a Time» publicado no jornal The New York Times relatou que os utilizadores da Internet tinham acabado de digitalizar o arquivo do jornal, publicado desde 1851, utilizando o reCAPTCHA. De acordo com o criador do reCAPTCHA na altura, os utilizadores, ou melhor «utilizados», decifravam cerca de 200 milhões de CAPTCHAs por dia, demorando 10 segundos para resolver cada um deles. Isto equivale a 500 000 horas de trabalho por dia2.
Um CAPTCHA pode ser utilizado não só para textos de difícil compreensão, mas também para imagens. Por exemplo, o Google também faz uso de reCAPTCHAs para identificar imagens de lojas, sinalização rodoviária, etc., feitas para o Google Maps. Os reCAPTCHAs do Google são também utilizados para outros fins que não são conhecidos pelos utilizados.

Só o Google sabe o lucro que obtém com este sistema de exploração. É impossível auditar o reCAPTCHA porque é um programa proprietário, e aqueles que o utilizam não têm qualquer poder. Tudo o que podem fazer é recusar-se a resolver CAPTCHAs como os do Google para impedir serem utilizados.
O Google utiliza agora um método de identificação que poupa tempo aos utilizadores e evita que estes tenham de decifrar textos e imagens. Os utilizadores agora só têm de clicar num botão. Este mecanismo impõe a execução de código JavaScript desconhecido pelos «utilizados», o que representa um grande perigo para a privacidade. O Google pode obter muita informação dos «utilizados» que utilizam este mecanismo, que provavelmente depois venderá por grandes somas de dinheiro.
Além disso, reCAPTCHA discrimina contra utilizadores deficientes e utilizadores do Tor: por um lado, os desafios apresentados aos utilizadores deficientes são mais longos e mais difíceis de resolver; por outro lado, aqueles que navegam na Internet a título privado têm de resolver um desafio mais difícil e demorado.
O artigo escrito pelo criador do reCAPTCHA3 quando foi adquirido pelo Google dizia:
Melhorar a disponibilidade e acessibilidade de toda a informação na Internet é realmente importante para nós, por isso estamos ansiosos por fazer avançar esta tecnologia com a equipa da reCAPTCHA.
No entanto, o trabalho realizado utilizando o reCAPTCHA não está disponível ou acessível em muitos casos. Os dados são apresentados de uma forma que beneficia financeiramente o Google e outras empresas. Os utilizadores que ajudaram a digitalizar o arquivo do The New York Times têm de pagar vendo os anúncios quando consultam o arquivo que ajudaram a digitalizar sem receber nada em troca.
-
Deciphering Old Texts, One Woozy, Curvy Word at a Time (28 de março de 2011). The New York Times. Consultado o 5 de maio de 2017. ↩
-
Teaching computers to read: Google acquires reCAPTCHA (2009-9-16). Official Google Blog. Consultado o 5 de maio de 2017. ↩